S… happens and sometimes we just loose data disk on SAF servers.
Problem is that for performance reasons we thought in the beginning that RAID0 would be a good idea, so that’s what we used. And so if we loose one server disk we loose all the data on that server.
Recently it happened to not one but two servers : nansaf09 and nansaf10.
Once the disk has been changed, we now redo the filesystem as RAID5, in order to decrease the maintenance operations we have to perform to repopulate the data (below).
This document explains how to repopulate the servers with the data they had before the disk crash. “Repopulation” means we put the data back in the same server it was before the crash. That way datasets and/or user file collections do not have to be changed at all (at least for files which are retrievable).
Only data that is (still) available in alien can be recovered that way. Data stored on the SAF by any other way than an original staging from alien is irremediably lost.
Prerequisites
The procedure below assumes you’ve already used PoD on the SAF at least once, so you have a $HOME/.PoD/user_worker_sh script already. This script insures your grid proxy is transmitted to worker nodes so an alien-token-init yourname can be made without requiring you input your passphrase again.
Getting the file lists.
To be able to repopulate the servers with some data you need to get the list of files that were on this server.
In the case of nansaf09-10 we were fortunate enough that the disks gave some alarms first, so we had the time to make a list of files.
If that would not have been the case, the other option would have been to recover the file list from the list of datasets (see e.g. VAF::GetFilesFromServer for help performing this task).
Assuming we get a list in the format timestamp size filepath we extract a list with only the filepaths :
cut -d ' ' -f 3 current-data.list.18Jun2018-nansaf10 | cut -c 6- | grep "^/alice" | grep -v "raw" | grep -v "FILTER_"
Note that we explicitly ignore raw data files (as those are unlikely to be on disk and require special permission to be fetched massively) or filtered ones which do not exist on alien storages.
From that file list(s), the basic work is then basically to copy the files from alien to the server, by performing for each file :
TFile::Cp("alien:///path/file","root://nansaf09//path/file);
Copying the files.
The only trick is then to speed up the process (there are potentially a lot of files in one server) by parallelizing the copy.
For this we use the SAF workers themselves through Condor (same idea that was used to perform reconstruction or digit filtering).
The scripts to perform those tasks are to be found in the repopulate directory of the aafu repo, so you have to clone the code on nansafmaster3 :
> saf3-enter
$ cd $HOME
$ git clone https://github.com/aphecetche/aafu
$ cd aafu/repopulate
$ vaf-enter # to get a Root environment and an alien token
Check in the list-input.sh the name of the server you want to use and the number of files to be downloaded per job.
Before launching thousands of jobs, you may want to check the split filelists generated by list-input.sh :
$ # assume server is nansaf09
$ . ./list-input.sh
$ ls nansaf09.list.dir
Then launch the jobs :
$ condor_submit repopulate.condor
$ condor_q
And go fetch several coffees ;-)
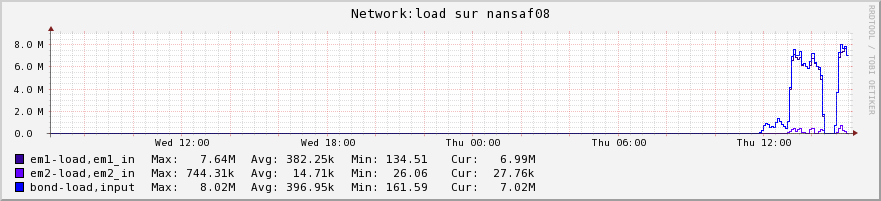
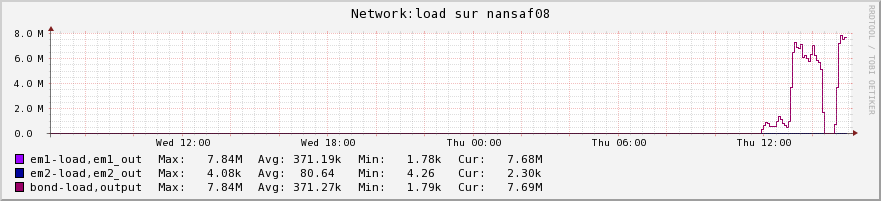
nagios monitoring will show you that all worker nodes, except the destination one (nansaf09 in this example) get incoming and outgoing traffic (they copy buffers of the input files -in memory only- before shipping it to the destination), while the destination server only gets incoming traffic.
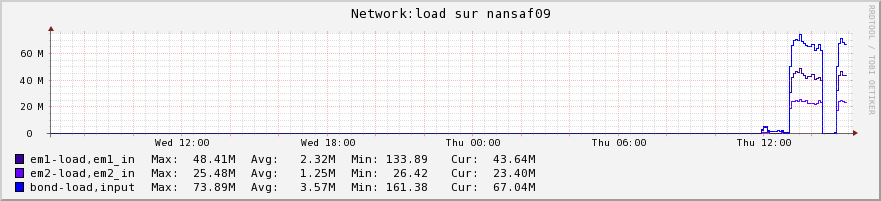
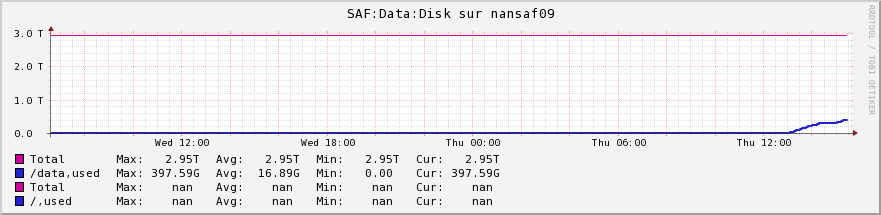
In addition, disk occupancy increases on the destination server.